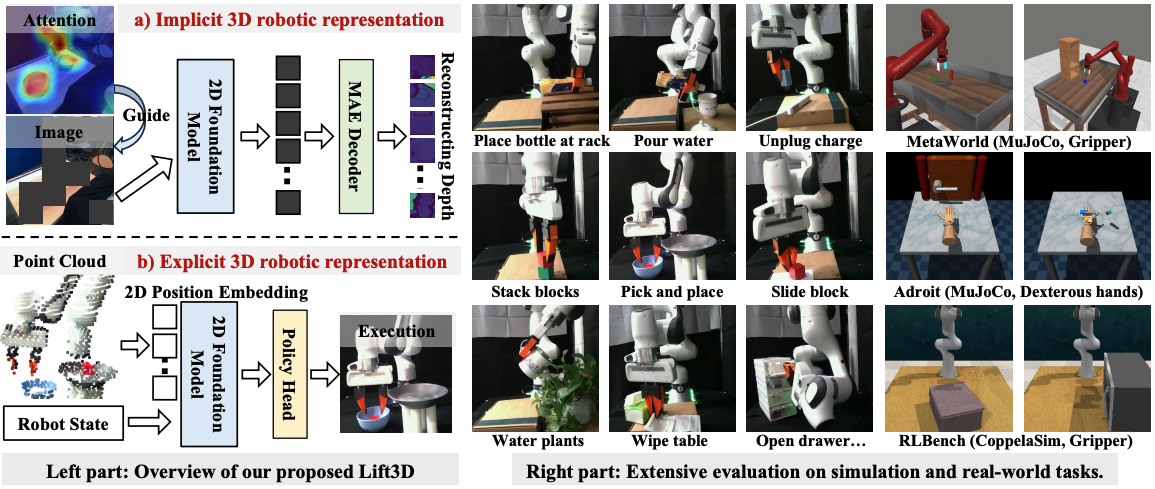
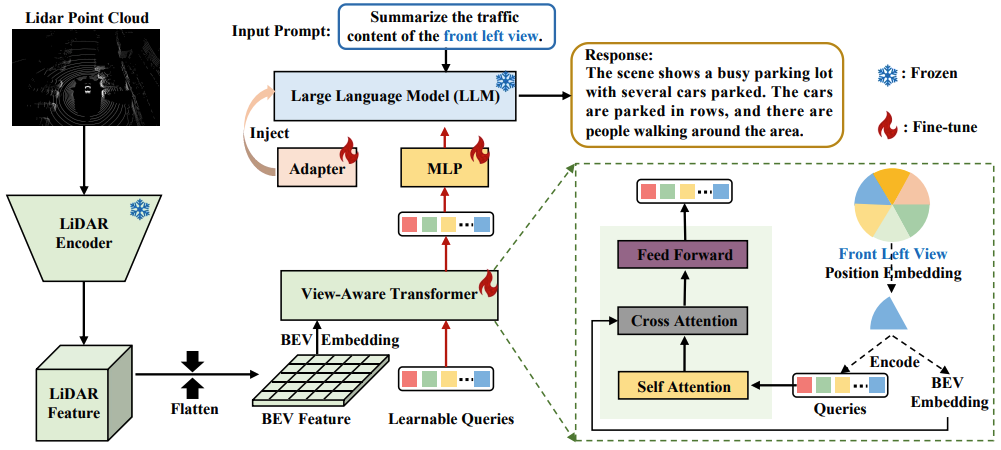
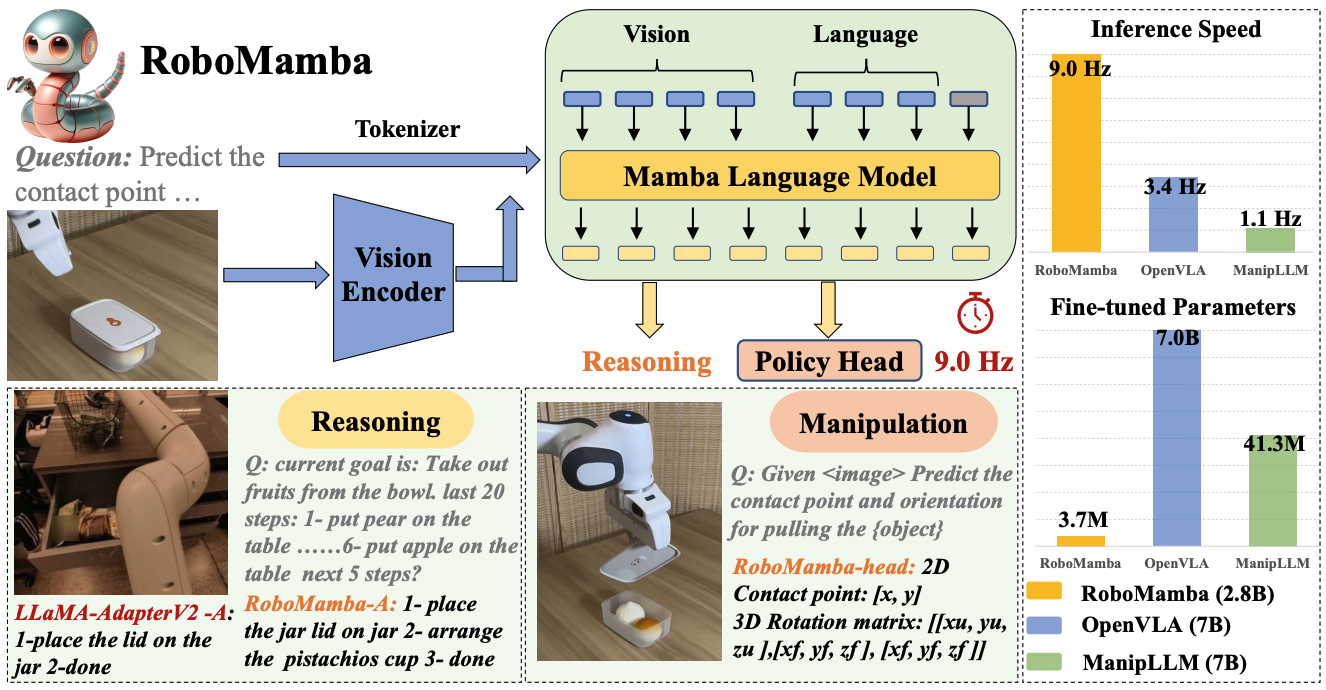
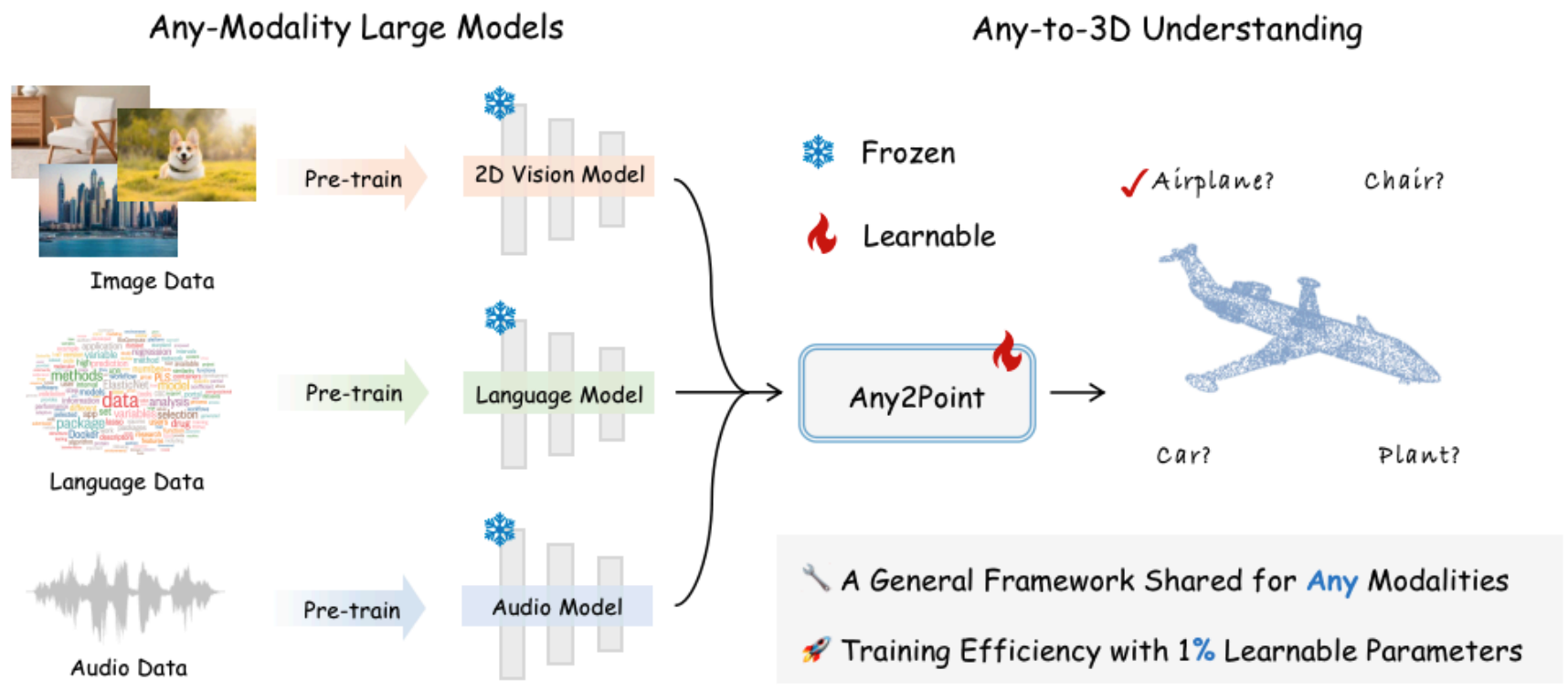
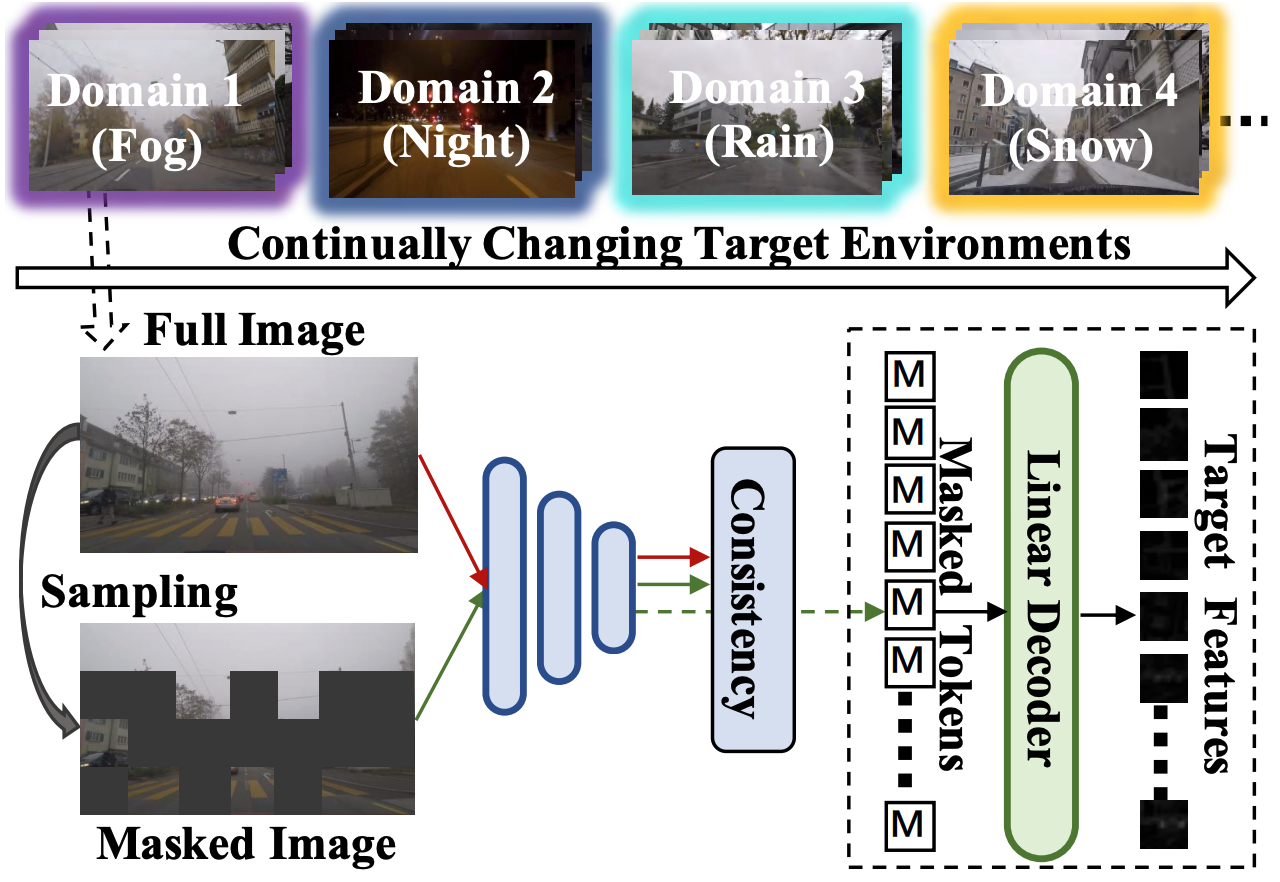
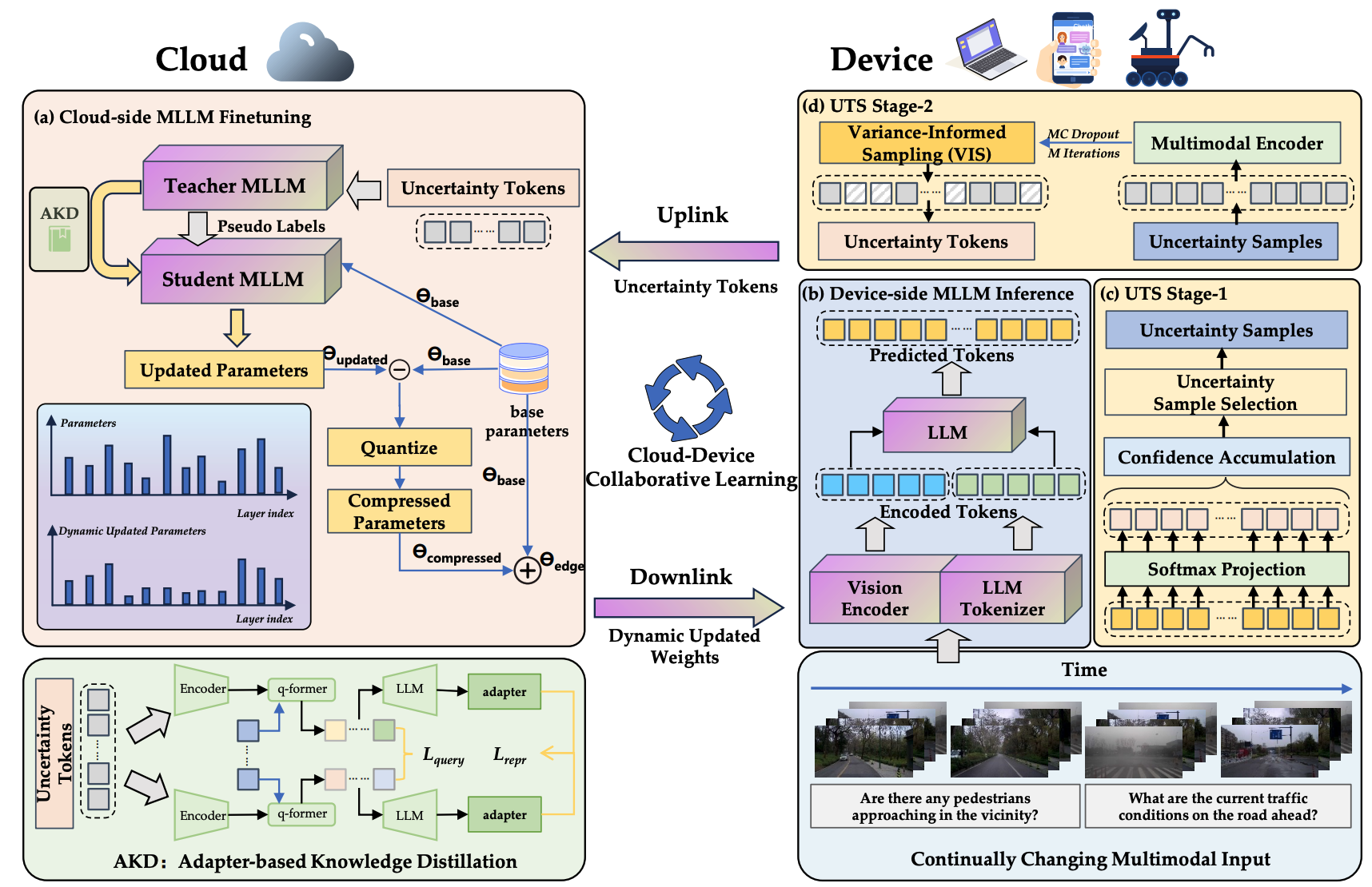
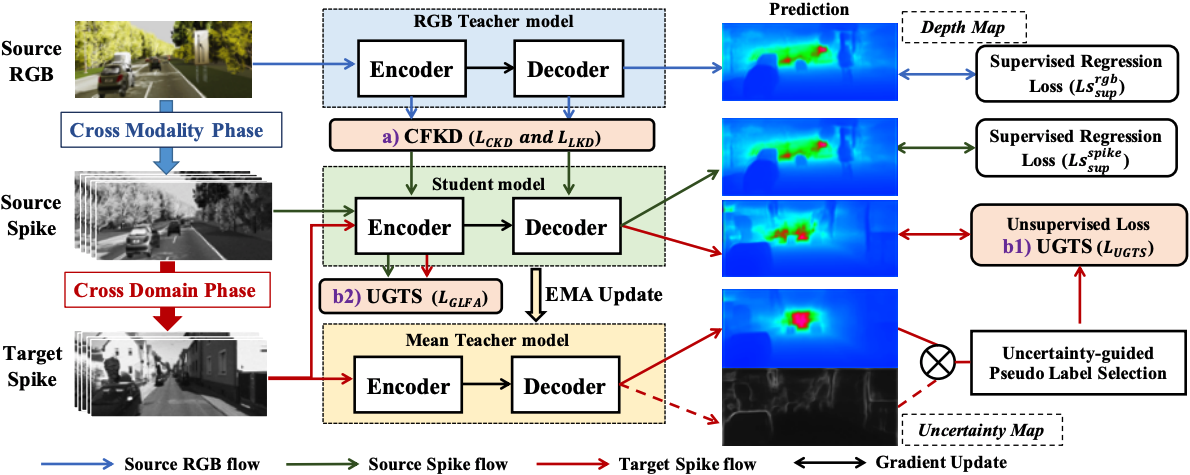
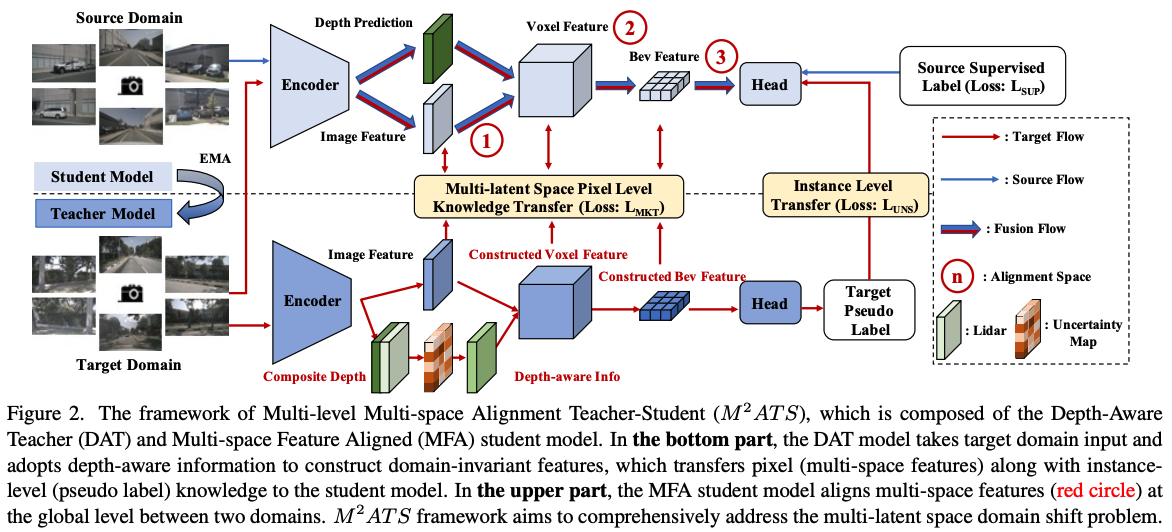
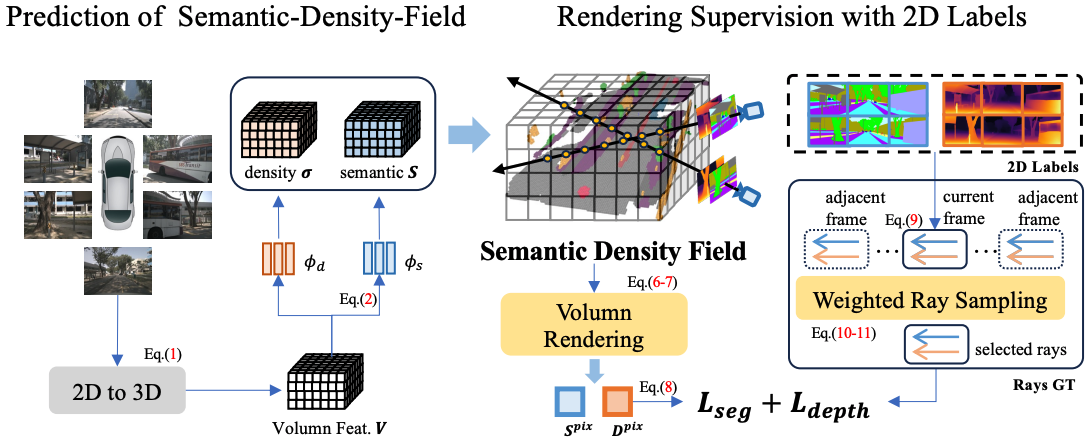
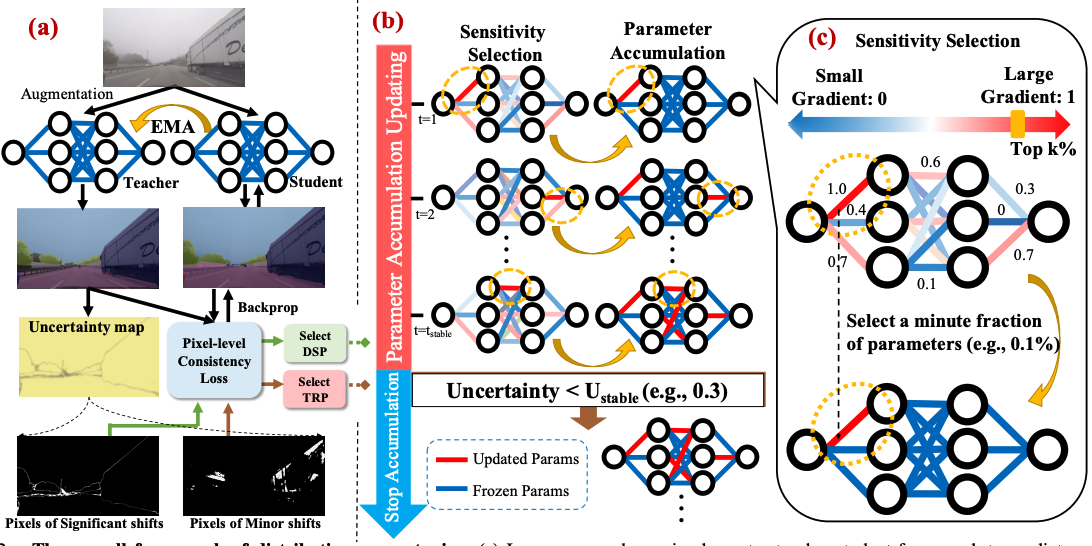
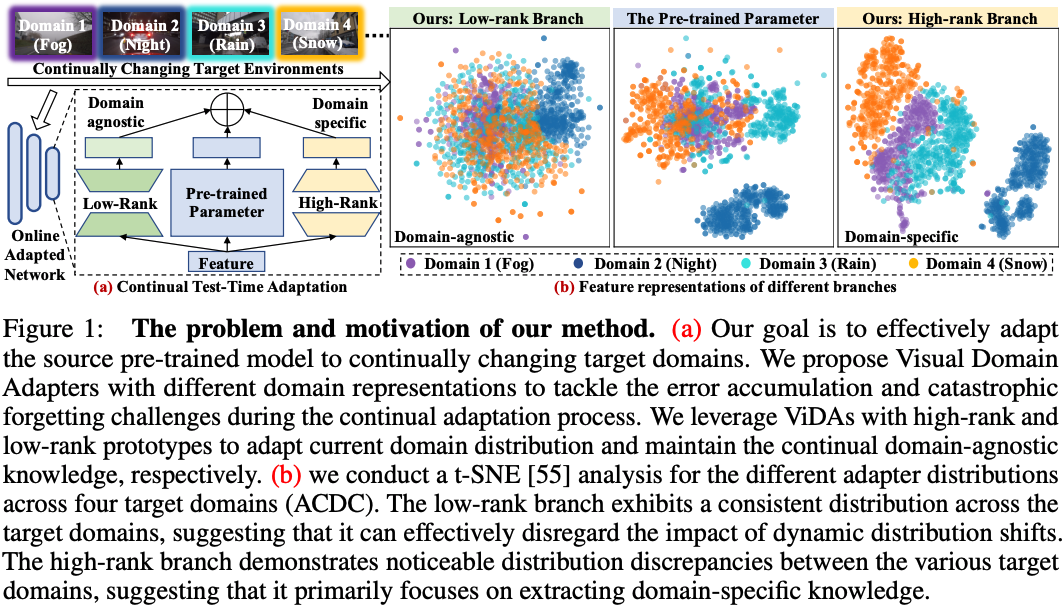
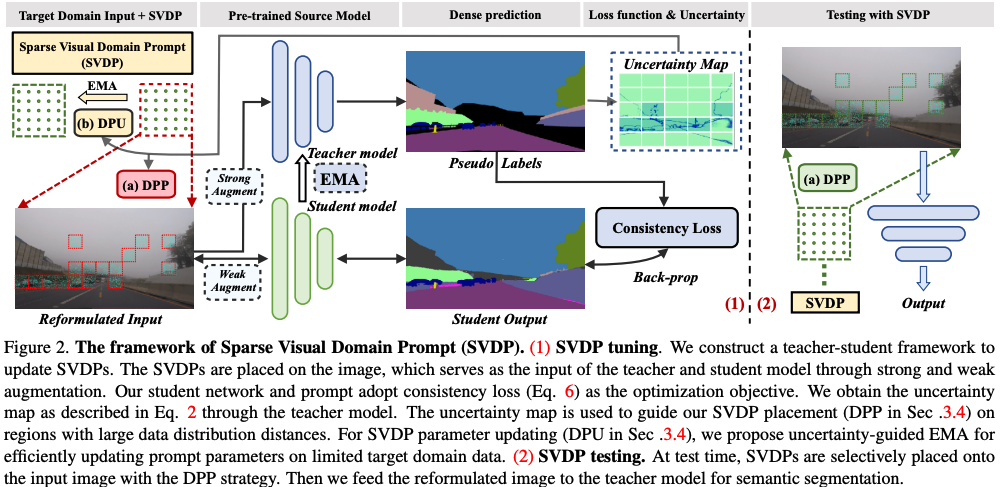
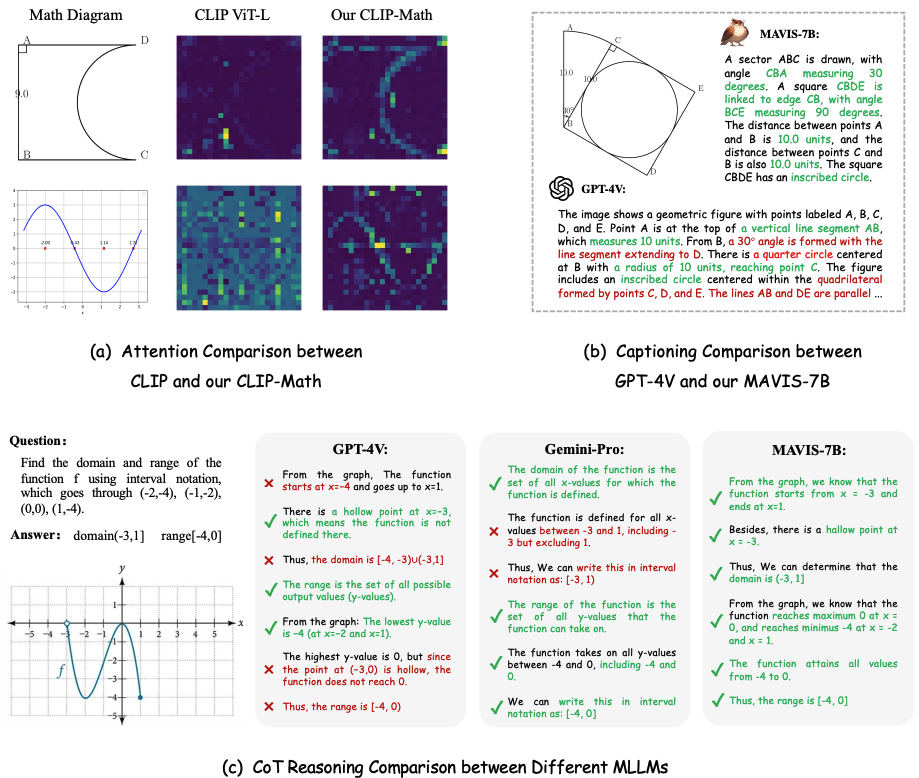
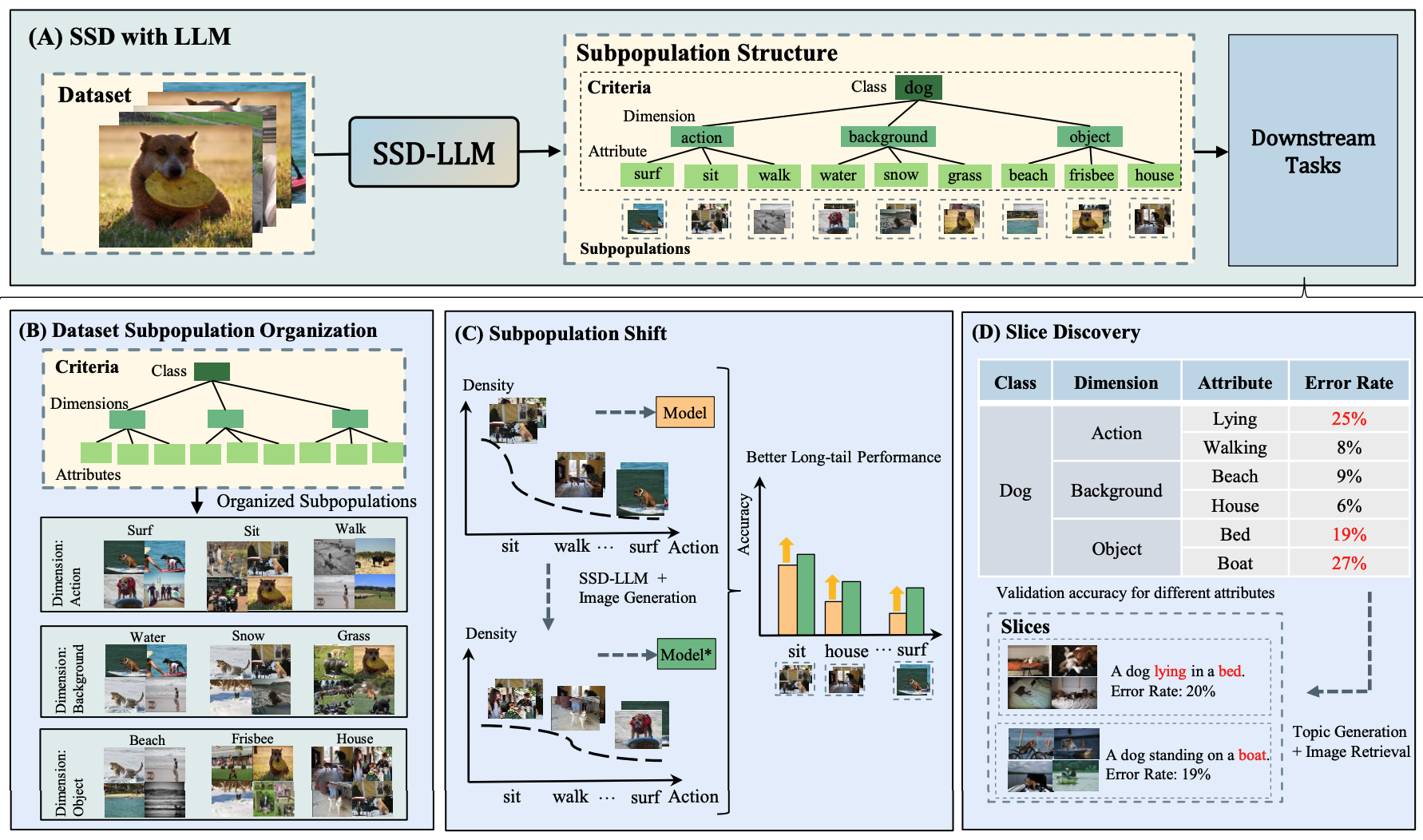
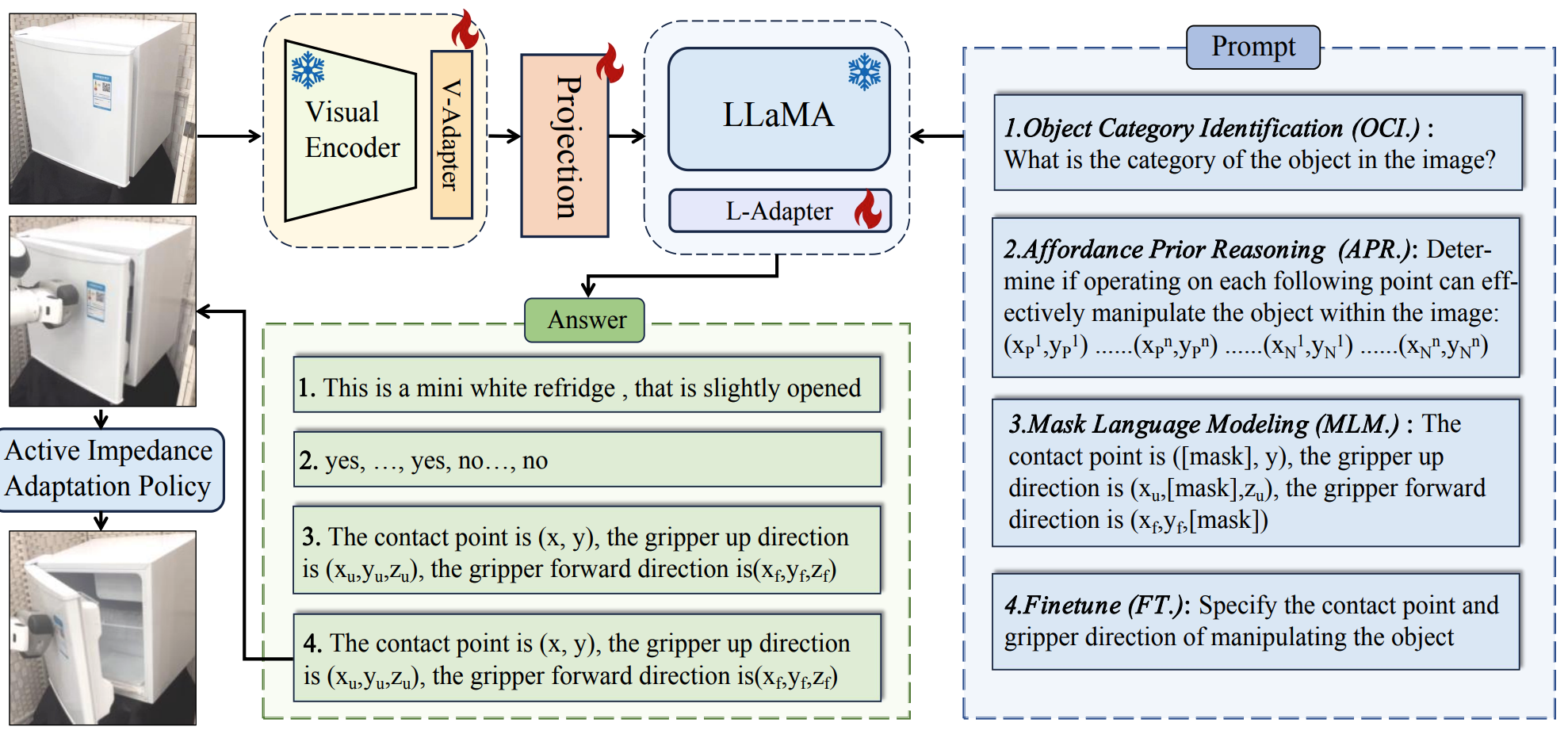
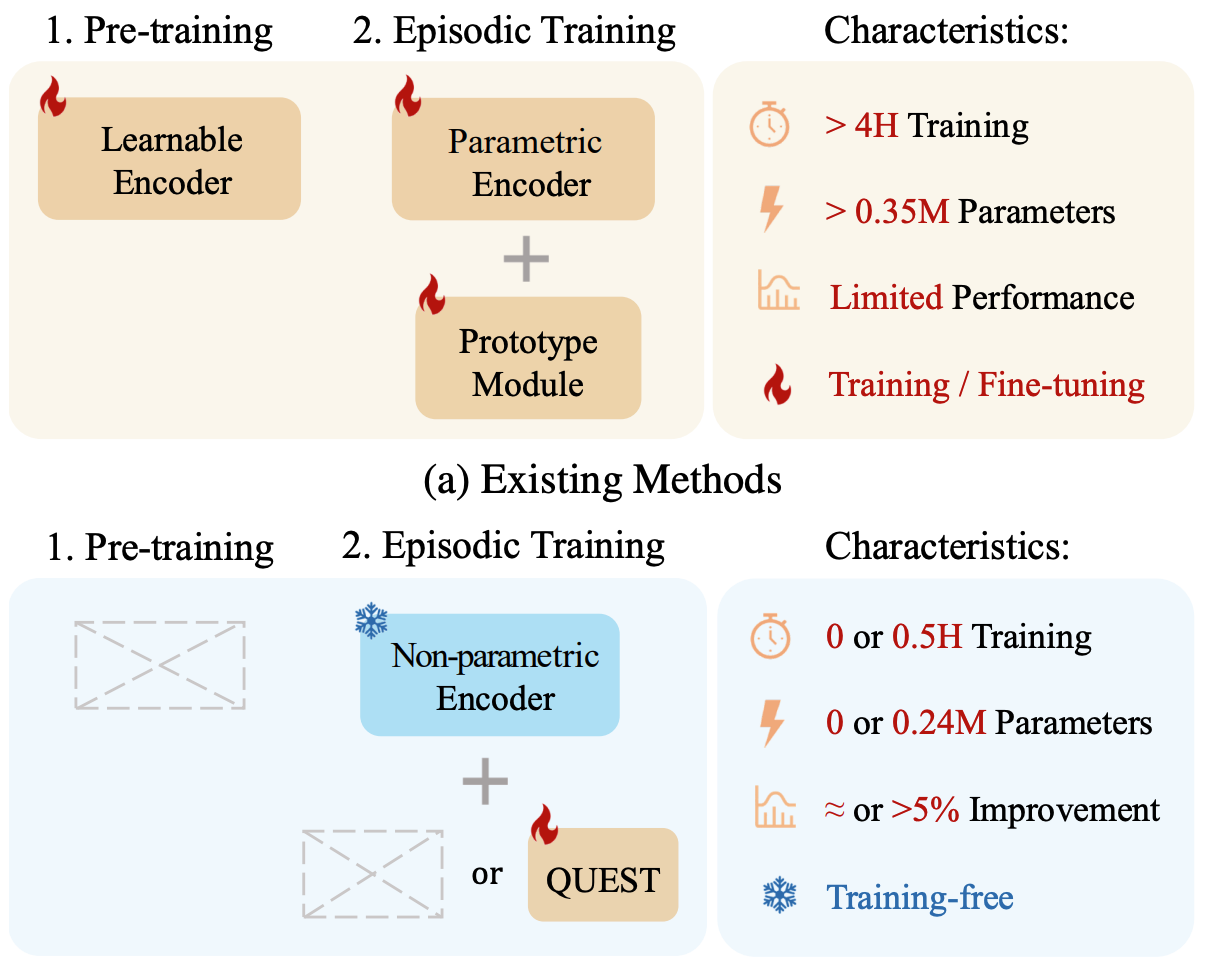
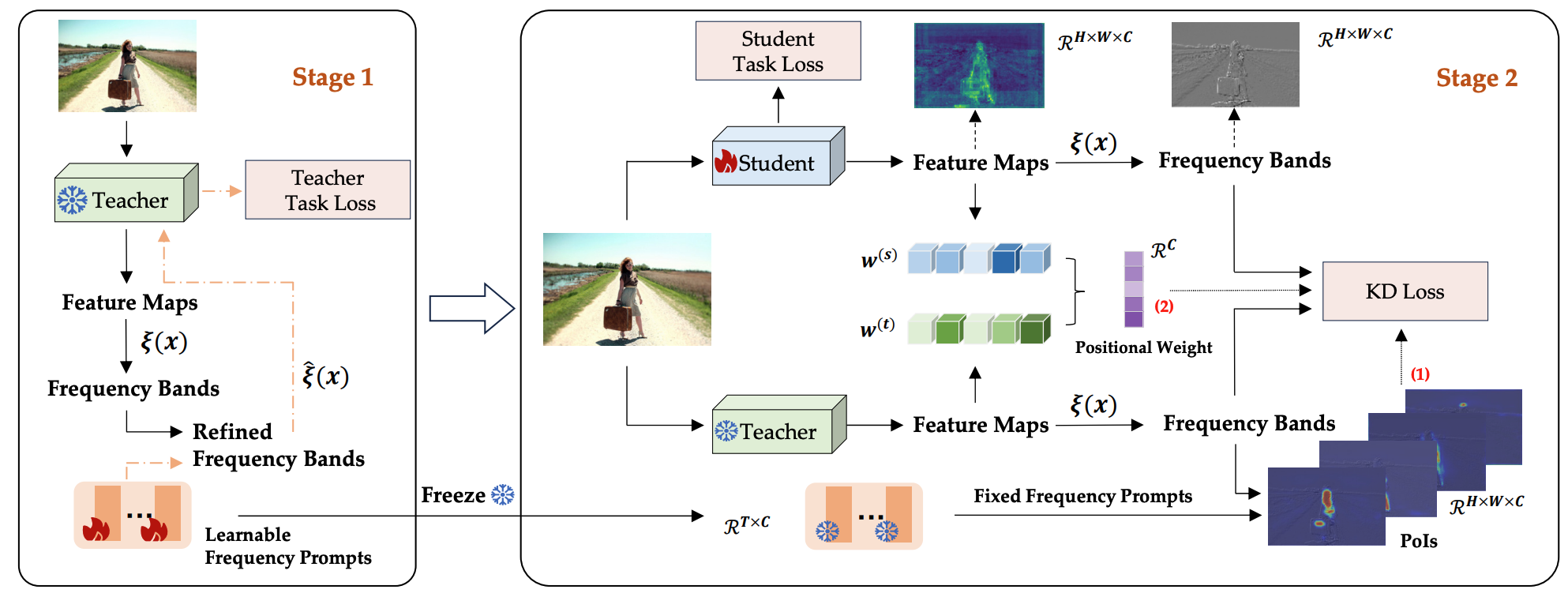
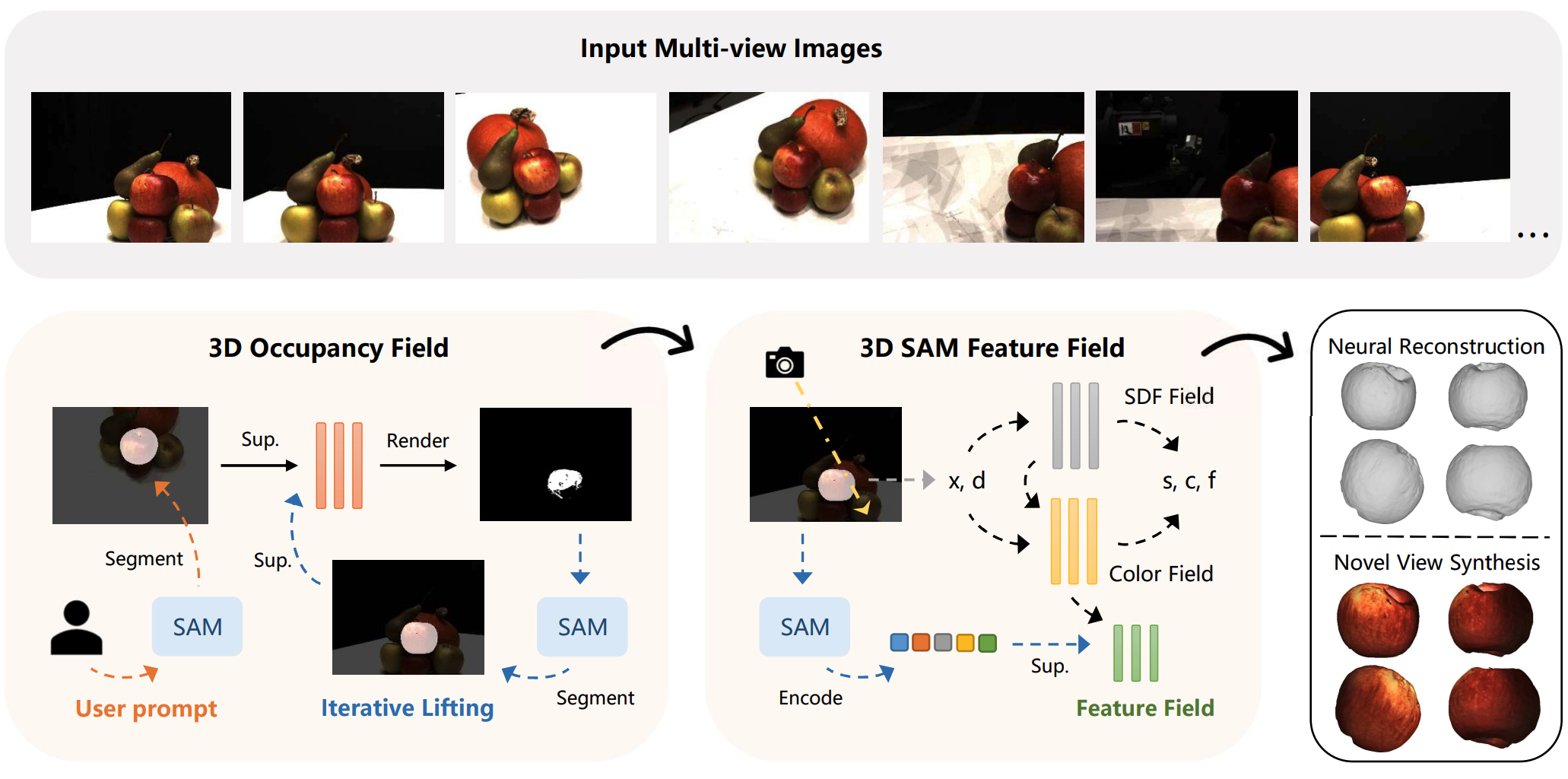
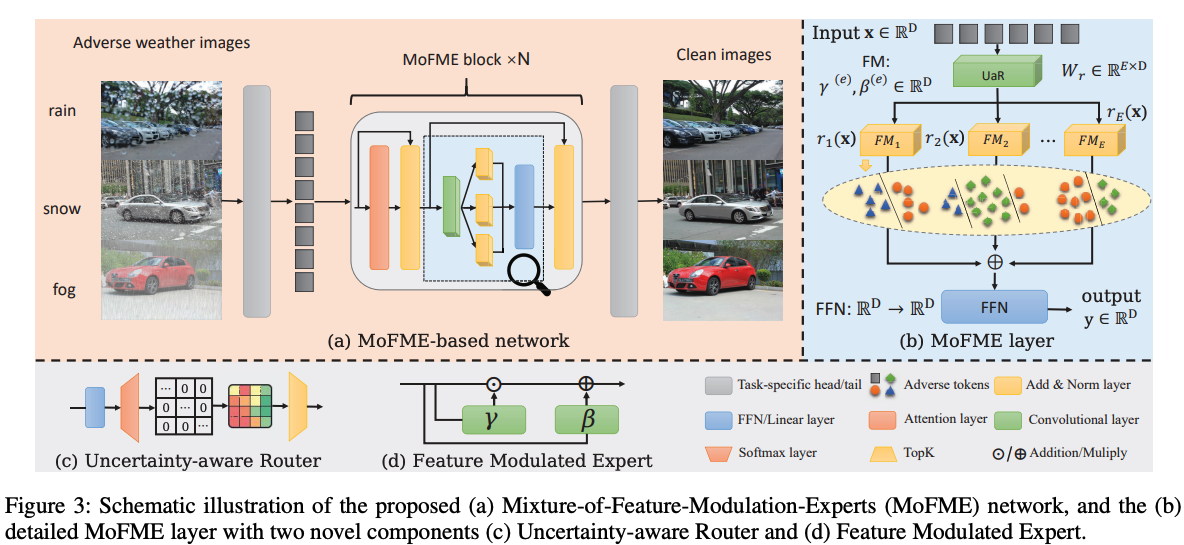
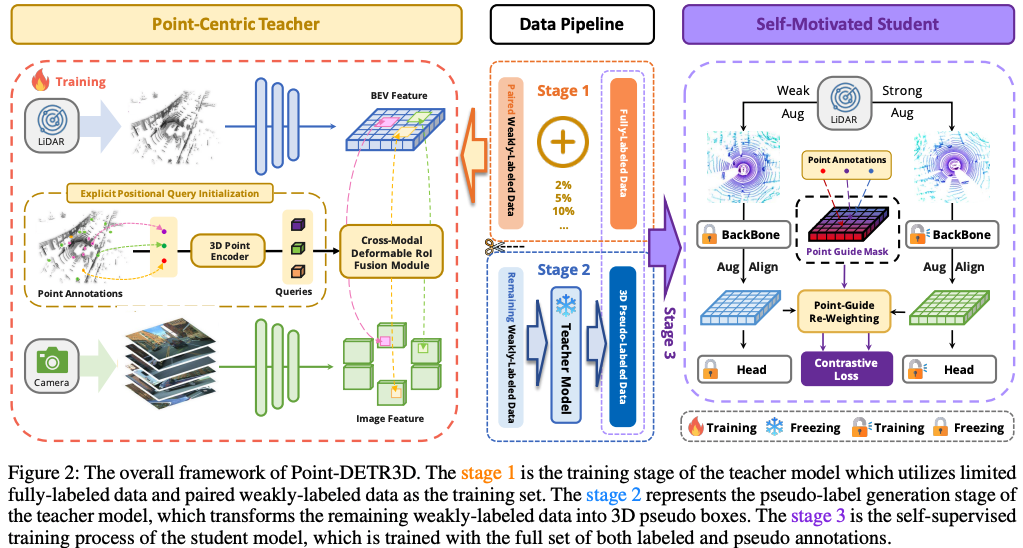
")
Liu Jiaming (刘家铭)
Bachelor degree (2015-2019)
北京邮电大学 Beijing University of Posts and Telecommunications
伦敦大学玛丽女王学院Queen Mary University of London
Master graduate (2019-2022)
北京邮电大学 Beijing University of Posts and Telecommunications
Pattern Recognition and Intelligent Systems Lab (PRIS Lab)
Employee (2022-2023)
OPPO研究院 OPPO Research Institute
Supervised by OPPO Chief Scientist - Yandong Guo
P.h.D candidate (2023-Now)
北京大学 Peking University, School of Computer Science
National Key Laboratory for Multimedia Information Processing
Email: jiamingliu@stu.pku.edu.cn
Bachelor degree (2015-2019)
北京邮电大学 Beijing University of Posts and Telecommunications
伦敦大学玛丽女王学院Queen Mary University of London
Master graduate (2019-2022)
北京邮电大学 Beijing University of Posts and Telecommunications
Pattern Recognition and Intelligent Systems Lab (PRIS Lab)
Employee (2022-2023)
OPPO研究院 OPPO Research Institute
Supervised by OPPO Chief Scientist - Yandong Guo
P.h.D candidate (2023-Now)
北京大学 Peking University, School of Computer Science
National Key Laboratory for Multimedia Information Processing
Email: jiamingliu@stu.pku.edu.cn